DockerでPostgreSQLを立ち上げる
開発作業を行う際、Dockerのsql系イメージとDBUnitを使ってテストを作っていたので、練習がてらこちらの記事にも書いていきます。
- バージョン関連
- ディレクトリ構成
- docker-compose.ymlの中身
- environment
- restart
- Dockerfileの中身
- ddl、dmlフォルダの中身
- docker compose でpostgresqlを立ち上げる
- DBeaverからPostgresqlコンテナにつなげてみる
- まとめ
バージョン関連
macOS Pro Monterey Apple M1 Docker 20.10.11, build dea9396 docker compose v2.2.1 DBeaver 23.0.5
ディレクトリ構成
のちのちの記事でSpring Bootを使うので、それに見越したフォルダ構成にします。
おそらくみなさんの環境には何もないと思いますが、何はともあれ下記のようなフォルダ構成やファイルを今回の目標として進めていきます。
# DBUnitApplication/ └── docker ├── docker-compose.yml └── postgresql ├── Dockerfile ├── ddl │ └── book_ddl.sql └── dml └── book_dml.sql
docker-compose.ymlの中身
dockerディレクトリ配下にdocker-compose.ymlファイルを作成します。
中身は下記です。
version: '3'
services:
postgresql:
container_name: postgresql_container
build: ./postgresql
ports:
- 5432:5432
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: passw0rd
TZ: "Asia/Tokyo"
restart: always
version
docker-composeで使用するバージョンを定義しています。詳細は公式ページとかをみてください(雑)。
services
アプリケーションを動かすための各要素。docker composeでは下記の例のように複数のコンテナを立てることができ、service以下に複数のコンテナを立てることができます。
ただ、今回はpostgresqlだけしかない状態です。
services
db:
〜〜
web:
〜〜
app:
postgresql
正確にはservices内で作成するコンテナのことで、ここの名前はなんでもいいです。
今回はpostgresqlのイメージを使うので、postgresqlと書いただけでした。
container_name
コンテナを立ち上げた際のコンテナの名前です。postgresqlのコンテナなので、postgresql_containerとしています。
build
Dockerfileが置いてあるパスを指定します。今回はdocker-compose.ymlから見て、postgresqlディレクトリ配下のところに置いてあるDockerfileを参考にしています。
ports
ポートを指定します。指定の仕方はホスト:コンテナとなります
Dockerはコンテナを立てた後、そのコンテナと通信を行うためには外部から通信できるポートを指定しなければコンテナにアクセスすることができません。
今回、コンテナ内部でpostgresqlサーバを立てており、それはpostgresqlのデフォルトのポート番号5432で動いています。そのため、ホスト:コンテナのコンテナ部分はホスト:5432となります。
一方、ホスト部分は外部からあるポートで来たときに内部のpostgresqlサーバで5432に繋ぐようになっています。この時のホスト部分から繋ぐ番号はわかりやすく5432としておきましょう。
つまり、ホスト:5432のホスト部分が5432:5432となり、これで外部からポート番号5432で来た場合に、コンテナ内部のPostgresqlサーバにポート番号5432で繋ぐことができます。
(この辺りのポート番号の指定の仕方をしっかり理解しておきたい場合は、ホスト側の番号を変えると理解しやすくなるかと思います。)
environment
postgresqlのイメージを使う際には必須の設定になります。ここら辺の設定は他の記事を参考にしてください。
restart
コンテナを再起動するかどうかのオプションです。alwaysを設定した場合、コンテナが落ちた際は再起動するようになっています。
で、これが役に立つのは大体OSを再起動した時でしょうか。OSを再起動する場合はほとんどのアプリケーションを止めることになるので、OS再起動後にDocker側で自動でコンテナを再起動するようにするには、必要な設定になっています。
Dockerfileの中身
dockerディレクトリ > postgresqlディレクトリ配下にDockerfileを作成します。
中身は下記です。
FROM postgres:latest COPY ./ddl/* /docker-entrypoint-initdb.d COPY ./dml/* /docker-entrypoint-initdb.d
FROM イメージ名
FROM句でイメージ名を指定します。今回はpostgresqlの最新(latest)のイメージを利用します。
COPY 第一引数 第二引数
COPY句はDockerfileがあるパスから見て、第一引数にあるものをコンテナ内部の第二引数の部分にコピーする方法です。
ここでsql系のイメージを使う場合、コンテナが起動したと同時に、sql系のサーバに初期データなどを投入しておきたいなどがあるかと思います。
その場合、Dockerのsql系のイメージは大体docker-entrypoint-initdb.dというディレクトリがあります。
ここに必要なファイル(sqlファイル系)を配置するようにすると、コンテナ起動と同時に、必要な設定や初期データを自動で入れてくれます。
ddl、dmlフォルダの中身
ddlとは、データ定義言語(DDL: Data Definition Language)のことで、SQLのCREATE TABLEステートメントなどを指します。
一方、dmlはデータ操作言語(DML: Data Manipulation Language)のことで、SELECT、UPDATE、DELETEステートメントなどを指します。
まぁ、一番最初のDBの枠を作るのがDDLで、具体的にデータの操作を行うのがDMLと覚えておけばいいでしょう。
ddlの中身
中身はシンプルで、ddlフォルダの中にbook_ddl.sqlファイルを置いてあるだけです。book_ddl.sqlの中身は下記になります。
-- DBの作成 create database db_books; -- DBの選択 \connect db_books; -- スキーマの作成 create schema books; -- スキーマの選択 SET search_path = books; -- テーブルの作成 create table book ( id serial PRIMARY KEY NOT NULL, title varchar(100) NOT NULL, author varchar(10) NOT NULL, created timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL, updated timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL );
最初のcreate schemaでbooksというスキーマを作成し、そのbooksというスキーマの中にbookというテーブルを作成しています。
具体的なsqlの型などはここでは割愛します。
dmlの中身
こちらも中身はシンプルで、dmlフォルダの中にbook_dml.sqlファイルを置いてあるだけです。book_dml.sqlの中身は下記になります。
-- DBの選択 \connect db_books; -- スキーマの選択 SET search_path = books; -- データの挿入 insert into book (title, author) values ('営繕かるかや怪異譚', '小野不由美'); insert into book (title, author) values ('営繕かるかや怪異譚 その弐', '小野不由美'); insert into book (title, author) values ('営繕かるかや怪異譚 その参', '小野不由美');
search_pathでbooksというスキーマを指定し、そのスキーマの中のbookテーブルにデータを入れています。
docker compose でpostgresqlを立ち上げる
さて、ここまでくればDockerを使って、postgresqlを立ち上げることができます。
ターミナルからdocker-compose.ymlファイルがあるディレクトリ(dockerディレクトリ)に移動し、下記でコンテナを立ち上げます。
# docker compose up -d --build Sending build context to Docker daemon 1.05kB Step 1/3 : FROM postgres:latest ---> bc5d09b9811d Step 2/3 : COPY ./ddl/* /docker-entrypoint-initdb.d ---> Using cache ---> 884adf10e417 Step 3/3 : COPY ./dml/* /docker-entrypoint-initdb.d ---> Using cache ---> 10a346435f9b Successfully built 10a346435f9b Successfully tagged docker_postgresql:latest Use 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them [+] Running 2/2 ⠿ Network docker_default Created 0.0s ⠿ Container postgresql_container Started 0.0s
docker ps(もしくはdocker container ls) として、コンテナがちゃんと起動しているか確認します。
# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6df61fb84222 docker_postgresql "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:5432->5432/tcp postgresql_container
上記のように出てくれば、一旦は大丈夫です。
DBeaverからPostgresqlコンテナにつなげてみる
DBeaverを利用して、先ほど立ち上げたPostgresqlコンテナにつなげてみましょう。 (DBeaverと言っていますが、正直、繋がるのであればどんなクライアントツールでもいいと考えています。WindowsだとA5SQLが有名でしょうか??)
DBeaverは下記の公式ページからダウンロードしてください。
さて、DBeaverを開いたら、接続設定を行います。
① 左上の接続ボタンを押下

② PostgreSQLを選択し、次へを押下

③ 下記項目を設定していきます。
Connect by:Host
Host:0.0.0.0
Port:5432
Database:postgres
ユーザー名:postgres
パスワード:passw0rd

いくつか注意点があります。
Port:DBeaverのPortでは、docker-compose.ymlのportsで設定した部分のポート番号を記載します。ここで注意しないといけないのは、ホスト:コンテナのホストのポート番号を記載することです。
仮に5500:5432などと設定していた場合は、DBeaverのPortは5500を設定してください。
Database:特にdocker-compose.ymlやDockerfileで、DBの設定をしていなければ、デフォルトのpostgresで問題ありません。設定を変えていた場合、それに合わせて、変更が必要です。
ユーザー名:docker-compose.ymlで記載したユーザ名を記載します。今回はPOSTGRES_USERにpostgresを指定しているので、postgresになります。
パスワード:docker-compose.ymlで記載したパスワードを記載します。今回はPOSTGRES_PASSWORDにpassw0rdを指定しているので、postgresになります。
④ 設定し終わったら左下のテスト接続を押下します。
接続済み(下記画面)と出てきたら「OK」を押下し、(③の画像の)右下の「終了」を押下します。

さて、実際にDBeaverにデータが入っているか見てみましょう。

dmlで設定した3データがちゃんと入っていることが確認できましたね。
今回はここまでです。
まとめ
何はともあれ、Dockerの練習も兼ねてPostgreSQLをDockerで立てることができましたね。次回からはSpring Bootを導入して、実際にデータにアクセスしてみたいと思います。
また、これまでのものを整理すると下記のようになっています。
ディレクトリ構成
# DBUnitApplication/ └── docker ├── docker-compose.yml └── postgresql ├── Dockerfile ├── ddl │ └── book_ddl.sql └── dml └── book_dml.sql
docker-compose.ymlの中身
version: '3'
services:
postgresql:
container_name: postgresql_container
build: ./postgresql
ports:
- 5432:5432
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: passw0rd
TZ: "Asia/Tokyo"
restart: always
Dockerfileの中身
FROM postgres:latest COPY ./ddl/* /docker-entrypoint-initdb.d COPY ./dml/* /docker-entrypoint-initdb.d
book_ddl.sqlの中身
-- DBの作成 create database db_books; -- DBの選択 \connect db_books; -- スキーマの作成 create schema books; -- スキーマの選択 SET search_path = books; -- テーブルの作成 create table book ( id serial PRIMARY KEY NOT NULL, title varchar(100) NOT NULL, author varchar(10) NOT NULL, created timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL, updated timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL );
dmlの中身
-- DBの選択 \connect db_books; -- スキーマの選択 SET search_path = books; -- データの挿入 insert into book (title, author) values ('営繕かるかや怪異譚', '小野不由美'); insert into book (title, author) values ('営繕かるかや怪異譚 その弐', '小野不由美'); insert into book (title, author) values ('営繕かるかや怪異譚 その参', '小野不由美');
DB2mermaidを使ってMySQLからER図を描く
MySQLからER図を描くとき、面倒臭いとか思ったりしたことはありませんか!!
そんなときにER図を描く手間を減らしてくれる、便利なツールDB2mermaidがあったので簡単に紹介します!
本日の主役
DB2mermaid · PyPI
環境
| ツール名 | バージョン |
|---|---|
| MacBook Pro(M1 mac) | mac OS Monterey 12.2.1 |
| DB2mermaid | 1.0.3 |
| Python | 3.10.9 |
| mysqlclient | 2.1.1 |
| SQLAlchemy | 2.0.7 |
| Docker | 20.10.11 |
| Docker Compose | v2.2.1 |
| MySQL(Docker Imageで代用) | 5.7 |
| DBeaver Community Edition | 23.0.0.202303040621 |
フォルダ構成
最終的に下記のようになりました。
db2mermaid ├── docker │ ├── Dockerfile │ ├── docker-compose.yml │ └── mysql │ ├── 00-sakila-schema.sql │ ├── 10-sakila-data.sql │ └── sakila.mwb └── main.py
環境構築
DB2mermaidの公式を見るとRequireに
- Python3.10
- sqlalchemy
- mysqlclient
- your (mysql)DB
とあるため、これを参考に環境を作成していきます。
仮想環境の作成
condaで仮想環境を用意しました。
# conda create -n db2mermaid python=3.10 #仮想環境の作成 # conda activate db2mermaid # db2mermaidをactivate
必要なパッケージのインストール
必要なパッケージとしてsqlalchemyやmysqlclientが書かれていますが、パッケージが入っていなくてもおそらくDB2mermaidをインストールするときに勝手に最新版のパッケージを取得してくれるはずです。
# pip install DB2mermaid
私は下記の順番でインストールしました。
# pip install SQLAlchemy # pip install mysqlclient # pip install DB2mermaid
DockerでMySQLを起動
サンプルデータの取得
DockerでMySQLを起動しデータを投入していきます。 データですが、DB2mermaidの公式を見るとどうやらSakilaを使っているようですので、そちらを利用します。
https://downloads.mysql.com/docs/sakila-db.tar.gz
上記をダウンロードし、db2mermaid/docker/mysql配下にsakila-schema.sqlとsakila-data.sqlとsakila.mwbを配置します。
docker
├── Dockerfile
├── docker-compose.yml
└── mysql
├── 00-sakila-schema.sql
├── 10-sakila-data.sql
└── sakila.mwb
このとき、ファイル名は00-sakila-schema.sql、10-sakila-data.sqlに変えておきましょう。
Dokerfileの作成
dockerディレクトリ配下に、Dockerfileを作成します。
FROM --platform=linux/x86_64 mysql:5.7 COPY ./mysql/*.sql /docker-entrypoint-initdb.d/
FROM部分に--platform=linux/x86_64が入っていますが、M1Macで必要な記載になります。
WindowやIntel Mac系は要らないはずです。
下記記事が参考になるかもしれません。
M1Mac環境でDockerのMySQLを動かす - Qiita
docker-compose.ymlの作成
dockerディレクトリ配下に、docker-compose.ymlを作成します。
version: '3'
services:
mysql:
container_name: mysql_container
build:
context: .
dockerfile: Dockerfile
ports:
- 3306:3306
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: sakila
MYSQL_USER: user
MYSQL_PASSWORD: password
TZ: "Asia/Tokyo"
restart: always
ここまでくると、下記のようなディレクトリ構成になっているはずです。
docker
├── Dockerfile
├── docker-compose.yml
└── mysql
├── 00-sakila-schema.sql
├── 10-sakila-data.sql
└── sakila.mwb
MySQLを起動
dockerディレクトリ配下で、下記コマンドを実行します。 実行後は特にエラーが起きなければ、正常に起動できているはずです。
# docker compose up -d --build # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d2c54b60b1ac docker_mysql "docker-entrypoint.s…" 2 seconds ago Up 2 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp mysql_container
DBeaverで接続確認
DBeaverを利用して実際にMySQLに接続できるか確認してみましょう。
DBeaverについて簡単に説明すると、マルチプラットフォームデータベースツールで、MySQLだけでなく、PostgreSQL、Sql Server、MariaDBなど様々なデータベースをサポートしています。
詳しい使い方などは、公式などを参考にしてください。
接続方法は下記の通りです。
① DBeaverを開く
② 接続を選択
③ MySQLを選択
色々ありますが、今回はMySQL(左上)を選択します。

④ 下記のように設定
Server host:127.0.0.1
port:3306
Databases::sakila
ユーザー名:root
パスワード:passowrd
パスワードですが、ユーザ名がrootになっているため、docker-compose.ymlで指定したMYSQL_ROOT_PASSWORDのpasswordを入れます。

⑤ テスト接続
テスト接続を押下し、接続が確認できればOK

実際にSQLを叩いてみると接続できていることがわかります。

DB2mermaidを利用する
DB2mermaidを利用して、先ほどのMySQLのER図を作成してみましょう。
Pythonファイルの作成
DB2mermaidに記載のある通りに書けば動きますので、その通りにコードを書いていきます。
db2mermaidディレクトリ配下にmain.pyを作成します。
公式に書いてあるuserやdb_nameは適切なものに書き換えます。
# coding:utf-8 from db2mermaid.db2mermaid import DB2Mermaid if __name__ == '__main__': dm = DB2Mermaid() dm.init_db("root", "password", "127.0.0.1", "3306", "sakila") dm.generate()
ここまでくると、下記のようなディレクトリ構成になっているかと思います。
db2mermaid ├── docker │ ├── Dockerfile │ ├── docker-compose.yml │ └── mysql │ ├── 00-sakila-schema.sql │ ├── 10-sakila-data.sql │ └── sakila.mwb └── main.py
実行してER図を取得する
main.pyを実行します。
# python main.py db_url: mysql://root:password@127.0.0.1:3306/sakila SAWarning: Did not recognize type 'geometry' of column 'location' self.meta.reflect(bind=engine) table name🌟 actor table name🌟 address table name🌟 city table name🌟 country table name🌟 category table name🌟 customer table name🌟 store table name🌟 staff table name🌟 film table name🌟 language table name🌟 film_actor table name🌟 film_category table name🌟 film_text table name🌟 inventory table name🌟 payment table name🌟 rental
実行が終わると、db2mermaidディレクトリ配下に下記のようなer.mdファイルが作成されます。
```mermaid
erDiagram
actor{
SMALLINT actor_id PK
VARCHAR(45) first_name
VARCHAR(45) last_name
TIMESTAMP last_update
}
address{
SMALLINT address_id PK
VARCHAR(50) address
VARCHAR(50) address2
VARCHAR(20) district
SMALLINT city_id FK
VARCHAR(10) postal_code
VARCHAR(20) phone
NULL location
TIMESTAMP last_update
}
city{
SMALLINT city_id PK
VARCHAR(50) city
SMALLINT country_id FK
TIMESTAMP last_update
}
country{
SMALLINT country_id PK
VARCHAR(50) country
TIMESTAMP last_update
}
category{
TINYINT category_id PK
VARCHAR(25) name
TIMESTAMP last_update
}
customer{
SMALLINT customer_id PK
TINYINT store_id FK
VARCHAR(45) first_name
VARCHAR(45) last_name
VARCHAR(50) email
SMALLINT address_id FK
TINYINT active
DATETIME create_date
TIMESTAMP last_update
}
store{
TINYINT store_id PK
TINYINT manager_staff_id FK
SMALLINT address_id FK
TIMESTAMP last_update
}
staff{
TINYINT staff_id PK
VARCHAR(45) first_name
VARCHAR(45) last_name
SMALLINT address_id FK
BLOB picture
VARCHAR(50) email
TINYINT store_id FK
TINYINT active
VARCHAR(16) username
VARCHAR(40) password
TIMESTAMP last_update
}
film{
SMALLINT film_id PK
VARCHAR(128) title
TEXT description
YEAR release_year
TINYINT language_id FK
TINYINT original_language_id FK
TINYINT rental_duration
DECIMAL(4_2) rental_rate
SMALLINT length
DECIMAL(5_2) replacement_cost
ENUM rating
SET special_features
TIMESTAMP last_update
}
language{
TINYINT language_id PK
CHAR(20) name
TIMESTAMP last_update
}
film_actor{
SMALLINT actor_id PK
SMALLINT film_id PK
TIMESTAMP last_update
}
film_category{
SMALLINT film_id PK
TINYINT category_id PK
TIMESTAMP last_update
}
film_text{
SMALLINT film_id PK
VARCHAR(255) title
TEXT description
}
inventory{
MEDIUMINT inventory_id PK
SMALLINT film_id FK
TINYINT store_id FK
TIMESTAMP last_update
}
payment{
SMALLINT payment_id PK
SMALLINT customer_id FK
TINYINT staff_id FK
INTEGER rental_id FK
DECIMAL(5_2) amount
DATETIME payment_date
TIMESTAMP last_update
}
rental{
INTEGER rental_id PK
DATETIME rental_date
MEDIUMINT inventory_id FK
SMALLINT customer_id FK
DATETIME return_date
TINYINT staff_id FK
TIMESTAMP last_update
}
```
作成されたER図を見る
作成されたer.mdからER図を可視化するには、オンラインエディタを使う場合とVScodeで見る方法など色々あります。
オンラインエディタの場合
オンラインエディタの場合、Mermaid Live Editorがあるので、そちらを利用します。
Online FlowChart & Diagrams Editor - Mermaid Live Editor
ただし、er.mdの中身をそのまま貼り付けるとエラーが出てしまいますので、er.mdファイルの上部にある```mermaidと下部にある```を削除して貼り付けましょう。
オンラインエディタ上では下記のようにしてみることが可能です。

VSCodeで見る場合
VSCodeで見る場合は、拡張機能でMarkdown Preview Mermaid Supportというものがあるので、それをインストールすればプレビュー機能(Macの場合:Cmd + k, v)から見ることが可能です。
まとめ
DB2mermaidを利用して、MySQLからER図を作成することができました。
ただ、今のところ対応しているのはMySQLのみで、また、テーブル間のリレーションも生成できないようです。
この辺りは将来的に対応してくれるのをゆっくり待ちましょう。( ̄∀ ̄)
その他:トラブルシューティングなど
mysqlclientインストール時のエラーについて
mysqlclientをインストールしようとすると、私の場合下記のエラーが出てきました。
Collecting mysqlclient
Using cached mysqlclient-2.1.1.tar.gz (88 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [16 lines of output]
/bin/sh: mysql_config: command not found
/bin/sh: mariadb_config: command not found
/bin/sh: mysql_config: command not found
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/private/var/folders/k7/x4m8rfmn2p1_xy7_24gdkvyc0000gn/T/pip-install-uc7mnp5y/mysqlclient_b7fe84c002c94e8ba150581772b02fdd/setup.py", line 15, in <module>
metadata, options = get_config()
File "/private/var/folders/k7/x4m8rfmn2p1_xy7_24gdkvyc0000gn/T/pip-install-uc7mnp5y/mysqlclient_b7fe84c002c94e8ba150581772b02fdd/setup_posix.py", line 70, in get_config
libs = mysql_config("libs")
File "/private/var/folders/k7/x4m8rfmn2p1_xy7_24gdkvyc0000gn/T/pip-install-uc7mnp5y/mysqlclient_b7fe84c002c94e8ba150581772b02fdd/setup_posix.py", line 31, in mysql_config
raise OSError("{} not found".format(_mysql_config_path))
OSError: mysql_config not found
mysql_config --version
mariadb_config --version
mysql_config --libs
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
上記の中にOSError: mysql_config not foundを見つけました。どうやらmysql_configがないらしい。
実際に探してみてもありませんでした。
# which mysql_config mysql_config not found
そんなこんなで探していると下記記事が見つかりまして。
mysql_config not foundとでたときの対処法 - Qiita
こちらの記事に書いてあることを順に上からやっていきます。
# brew install mysql-connector-c # echo 'export PATH="/opt/homebrew/opt/mysql-client/bin:$PATH"' >> ~/.zshrc # export PATH="/opt/homebrew/opt/mysql-client/bin:$PATH" # which mysql_config /opt/homebrew/opt/mysql-client/bin/mysql_config # chmod 777 /opt/homebrew/opt/mysql-client/bin/mysql_config
で、最後にviでmysql_configファイルを開いて編集するらしいのですが、私の場合は下記のようになっていたため、編集しなくてもいいと思い、今回は無視しました。
# vi /opt/homebrew/opt/mysql-client/bin/mysql_config ~省略~ libs="-L$pkglibdir" libs="$libs -lmysqlclient -lz -L/opt/homebrew/lib -lzstd -L/opt/homebrew/opt/openssl@1.1/lib -lssl -lcrypto -lresolv" ~省略~
再度pip install mysqlclientすることで無事installすることができました。
ファイル名を変える意味
サンプルデータの取得部分でファイル名を、00-sakila-schema.sql、10-sakila-data.sqlに変更した意味ですが、Dockerが関係しています。
DockerのSQL系のイメージは、コンテナ内の特定の場所にファイルを配置すると、ファイル名を元に自動的にデータベースを作成してくれます。
このときの実行順ですが、Dockerではファイル名順に実行します。
つまり、sakila-schema.sqlとsakila-data.sqlのままだと、sakila-data.sqlが先に実行され、sakila-schema.sqlが後から実行されることになり、テーブルなどの定義がないままデータを投入しようとしてDBの作成に失敗してしまいます。
sakila-data.sql # 1番目に実行 sakila-schema.sql # 2番目に実行
これを避けるため、ファイル名を00-sakila-schema.sql、10-sakila-data.sqlに変えたのでした。
MySQL系に限った話ではないですが、実行順には気をつけるようにしましょう。
参考記事
mysql_config not foundとでたときの対処法 - Qiita
M1Mac環境でDockerのMySQLを動かす - Qiita
統計学基礎vol.52〜単回帰分析〜
回帰とは
回帰とは、目的変数$ y $について説明変数$ x $を使った式で表すこという。
この式のことを回帰方程式、あるいは簡単に回帰式という。また回帰式を求めることを回帰分析という。
回帰式というと、おおよそ1次関数($ y = \beta_0 + \beta_1 x $、$ \beta_0$は切片、$ \beta_1$は傾き)をイメージされるかもしれませんが、実は1次関数だけではなく、2次関数や3次関数なども回帰式として求めることが可能です。
回帰分析と重回帰分析
回帰分析(単回帰分析)は説明変数が一つのもの(など)を求めることを言います。ちなみに、説明変数が一つであればいいので、
や
を求めることも単回帰分析になります。
一方、重回帰分析は説明変数が複数のものを求めることを言います。つまり、などのように説明変数が複数あれば重回帰分析となります。
単回帰分析と重回帰分析は理解してしまえば簡単なので、きちんと区別できるようにしておきましょう。
単回帰式における係数(重み)の求め方
単回帰式における
と
の求め方について考えていきましょう。
基本的には、測定、収集されたデータから真の回帰式を求めるため、を求めることができればいいのですが、現実の問題はそう簡単ではありません。
測定誤差やさまざまな誤差を含んでいることが考えられます。そのため、そのようなさまざまな誤差をまとめてとして考え、真の回帰式から実際のデータまでのズレを考えると下記のように考えることができます。
図にすると下記のような感じです。

さて、ここで仮に収集されたデータが個あれば、
、
もそれぞれ
個あります。そうなると、説明変数
と
と
で表現できる真の値は
となります。そして、実際に計測された値
との差が誤差となります。つまり、
番目のデータの誤差は
で求めることができます。
この全ての誤差データを小さくなるようにすれば、
と
を求めることができます。より詳しく書くと、次式で表されるようにそれぞれのデータの誤差
の二乗和を考え、この二乗和が最小となるような
と
を算出することで求めることができます。この方法を最小二乗法と言います。

※がいきなり出てきましたが、これは残差と呼ばれるもので、後程コラムで解説します。
最小二乗法により推定されたと
は「偏回帰係数」と呼ばれます。これらは実際のデータから算出された推定値であり、真の回帰式における
と
とは異なることから、「^ (ハット)」をつけて
と
と表します。
さて、以上を踏まえて上で、と
の求め方について省略した形ではありますが、簡単に説明します。
最小二乗法を用いて回帰式
の
と
を求める場合、下記式を
と
をそれぞれで偏微分した式を0とした2つの式を使います。
偏微分を計算し、整理すると下記のように求める式を求めることができます。

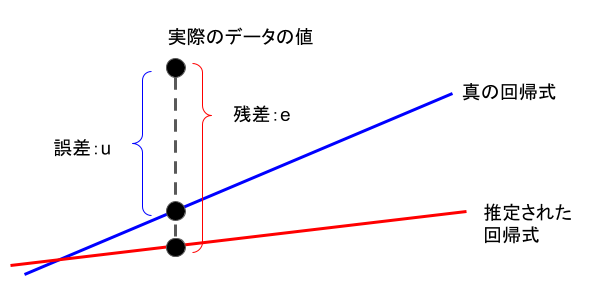
コラム:残差と誤差について
単回帰式における係数(重み)の求め方のところでがいきなり出てきましたが、これは残差と呼ばれるものです。
誤差は求めようとする真の回帰式から算出される値と実際のデータとの差を表しています。
一方、残差は実際のデータを用いて推定された回帰式から算出される値と実際のデータとの差を表しています。
図で表すと下記のようになります。
まとめ
| 用語 | 意味 |
|---|---|
| 回帰 | 目的変数 |
| 回帰分析 | 回帰方程式(回帰式)を求めること |
| 最小二乗法 | それぞれのデータの誤差 |
| 偏回帰係数 | 回帰分析において得られる回帰方程式の各説明変数の係数のこと |
| 誤差 | 真の回帰式から算出される値と実際のデータとの差 |
| 残差 | 推定された回帰式から算出される値と実際のデータとの差 |
統計学基礎vol.51〜無相関の検定と偏相関係数〜
気づいたら年が明けてました。だから何やねんって話ですが。
無相関の検定
標本から算出した相関係数を使って、母集団の相関係数が0かどうかを検定すること。
検定は自由度がの
分布を利用し、
は標本から算出した相関係数、
はサンプルサイズである。
母相関係数の信頼区間
次式を用いて標本から算出した相関係数を変換する。この変換をフィッシャーの
変換という。
同様に母相関係数を
変換したものを
とすると、
と表せる。
はサンプルサイズ
が大きい時には平均
、分散
の正規分布
に従う。これらを用いて
を標準化すると、

となる。
最後にを母相関係数
に戻し、
、
(ここで、LはLower、UはUpper)を次のように書く。

となる。
偏相関係数
2つの変数の相関が第3の変数によって高められる、または低められる場合に2変数から第3の変数の影響を取り除いて求めた相関係数のこと。
1つの因子を、2つ目の因子を
、3つ目の因子を
と置く。
と
の相関係数を
、
と
の相関係数を
、
と
の相関係数を
とする。これを用いて、
の影響を除いた
と
の偏相関係数
を表すと、
と表せる。
層別解析
データの中に幾つかの異なる性質の集団が含まれている場合、データを分割して解析すること。
例えば、各都道府県の年間日照時間と年間平均気温の関係を表すと、年間日照時間が長い都道府県ほど平均気温が高くなります。しかし、雪の多い都道府県と雪の少ない都道府県で層を分けて解析すると、雪が多いか少ないかで結果が変わってくることがあります。
まとめ
| 用語 | 意味 |
|---|---|
| 無相関の検定 | 標本から算出した相関係数を使って、母集団の相関係数が0かどうかを検定すること |
| 母相関係数の信頼区間 | 母相関係数 |
| 偏相関係数 | 2つの変数の相関が第3の変数によって高められる、または低められる場合に2変数から第3の変数の影響を取り除いて求めた相関係数のこと |
| 層別解析 | データの中に幾つかの異なる性質の集団が含まれている場合、データを分割して解析すること。 |
統計学基礎vol.50〜散布図と相関係数〜
さて、今回からは今までの仮説検定の話を終えて、散布図と相関係数の話に入ります。
長々とやってきた統計学基礎ですが、散布図関連と回帰分析だけを取り上げれば、このブログでの解説は終わろうかと思っています。
まぁ、あと2年ぐらいすれば終わるかもしれません。。。
散布図
2つの要素からなる1組のデータが得られた時に、2つの要素の関係を見るためにプロットしたグラフのこと。
ざっくり言えば下記のような画像になります。

データを散布図で表すと、1つ目の要素が変化したときに、2つ目の要素はどのように変化するかを確認することができます。また、2つの要素の間に何らかの関係がある時、これらのデータ間には
相関関係がある
と言います。
正の相関と負の相関と無相関
正の相関関係とは、横軸の値(など)が増加すると縦軸の値(
など)も増加するという関係のこと。例としては散布図のところで挙げた図がこれにあたります。
負の相関関係とは、横軸の値(など)が増加すると縦軸の値(
など)が減少するという関係のこと。
直線的な関係の傾向が強い場合、強い相関関係、逆の場合は弱い相関関係と言います。(この辺りの強い、弱いに関しては相関係数という値で計算できます。詳しくはこの後説明します。)
強い相関の例は下記のように、直線的な傾向が強く残っています。

弱い相関の例は下記のように、直線的な傾向はあるものの、上記と比べるとそこまで強くないことがわかります。

横軸が増加しても縦軸に増減の傾向が見られない場合は、相関関係なし(無相関)と言います。
無相関の例は下記になります。

相関関係と因果関係
相関関係は、2つの事象の間にある何らかの関係のことを言います。ただし、どちらかの事象がもう片方の事象の直接的な原因かどうかは不明です。
因果関係は、2つの事象のうち、一方が原因となって他方の結果があるという関係のことを言います。相関関係があるからといって、因果関係があるとは言えません。
相関係数
2つの要素と
からなる
コのデータ(
)が得られた時、その相関係数
は次の式から算出される。

分母は、
それぞれの標準偏差の積になっており、分子は
と
の共分散である。
また、相関係数の範囲は
で、相関係数が1、もしくは-1に近いほど相関が強く、0に近いほど相関が弱い。ただし、相関係数が0に近くても、何らかの関係がある場合がある。
相関係数は2つの要素の直線的な相関関係の強弱を表すもので、のような線形ではない相関関係の強弱は正しく表すことができない。そのため、相関係数
が0に近くても「相関がない」とは言い切れず、実際のデータをグラフにプロットして確認する必要がある。
目視で捉えることが必要である!
まとめ
| 用語 | 意味 |
|---|---|
| 散布図 | 2つの要素からなる1組のデータが得られた時に、2つの要素の関係を見るためにプロットしたグラフ |
| 正の相関関係 | 横軸の値( |
| 負の相関関係 | 横軸の値( |
| 強い相関関係 | 直線的な関係の傾向が強い |
| 弱い相関関係 | 直線的な関係の傾向が弱い |
| 相関関係なし(無相関) | 横軸が増加しても縦軸に増減の傾向が見られないもの |
| 相関関係と因果関係 | 相関関係は2つの事象の間にある何らかの関係のこと、因果関係は2つの事象のうち一方が原因となって他方の結果があるという関係。相関関係があるからといって因果関係があるとは言えない。 |
| 相関係数 |
2つの要素の相関を計算した値。範囲は |
| 相関係数の注意点 | 相関係数は2つの要素の直線的な相関関係の強弱を表すため、線形ではない相関関係の強弱は正しく表すことができない。目視で捉えることが必要。 |
統計学基礎vol.49〜母比率の差の検定〜
今のプロジェクトが煌々と燃えていまして。
炎上なんてものじゃないです。個人的には山火事レベル...。
そんなわけでだいぶ仕事したくない欲が非常に強いのです。何かの拍子に会社潰れないかなと思うぐらい。
さてさて、今回は母比率の差の検定です。
母比率の差の検定
2つの標本から得た標本比率を使って母比率が等しいかを検定すること。
例題
あるドラマの視聴率を調査すると、関東地区では5000世帯中、1000世帯が視聴していたことがわかった。一方、関西地区では3000世帯中540世帯が視聴していた。この結果から、2地区の視聴率に差があるといえるか。
| 関東地区 | 関西地区 | |
|---|---|---|
| 調査世帯数 | ||
| 視聴世帯数 |
母比率の差の検定の手順
母比率の差の検定ですが、(仮説)検定を行う以上、今まで見てきた下記手順と同じように行います。
- 仮説を立てる
- 有意水準を設定
- 適切な検定統計量を決める
- 棄却ルールを決める
- 検定統計量をもとに結論を出す
1 仮説を立てる
:関東地区と関西地区の視聴率は等しい
:関東地区と関西地区の視聴率は等しくない(差がある)
2 有意水準を設定
3 適切な検定統計量を決める
母比率の差の検定では、サンプルサイズが十分に大きい時には、統計量
は
に従う。
1群目の標本比率を
1群目のサンプルサイズを、
2群目の標本比率
サンプルサイズを
とする。
また、2つの標本比率を1つにまとめた標本比率(プールした標本比率)を使う。
帰無仮説は「視聴率は等しい」なので、となるため、上記のようになります。
また、
です。
4 棄却ルールを決める
標準正規分布を利用する。また、関東地区と関西地区とで視聴率の差があるかどうかを確認するため、両側検定を行う。
5 検定統計量をもとに結論を出す
さて、結論を出しましょう。
よって、

よって、有意水準において帰無仮説
を棄却し、対立仮説
を採択する。
つまり、関東地区と関西地区とで視聴率に差がある。
(ここではあくまで、視聴率に差があるということがわかっただけで、どれぐらいの差があるのかまではわかっていません。どれくらいの差があるかを求めるならさらに深く追求する必要があります。)
コラム:母比率の差の検定と正規分布の再生性
に従うとき、
が大きい場合、
に従う。また、これらの和もまた正規分布に従う。
を正規化した統計量
は正規分布に従う。
この母比率の差の検定は、帰無仮説を
としていることから、
としたときの
と
をプールした標本比率
を使って、次のように書き換えられる。
従って、
となる。
まとめ
| 用語 | 意味 |
|---|---|
| 母比率の差の検定 | 2つの標本から得た標本比率を使って母比率が等しいかを検定すること |
統計学基礎vol.48〜独立性の検定〜
今回は独立性の検定です。
独立性の検定
2つ以上の分類基準を持つクロス集計表において、分類基準に関連があるかどうかを検定すること。このような場合もカイ二乗分布による検定を行います。
例題
ランダムに得られた男女各100人の血液型について次のようなデータが得られた。この結果から、性別と血液型に関連があるといえるか?
| 血液型 | A型 | B型 | O型 | AB型 | 計 |
|---|---|---|---|---|---|
| 男性 | |||||
| 女性 | |||||
| 合計 |
独立性の検定の手順
独立性の検定ですが、(仮説)検定を行う以上、今まで見てきた下記手順と同じように行います。
- 仮説を立てる
- 有意水準を設定
- 適切な検定統計量を決める
- 棄却ルールを決める
- 検定統計量をもとに結論を出す
1 仮説を立てる
:性別と血液型は独立(関連がない)
:性別と血液型は独立ではない
2 有意水準を設定
3 適切な検定統計量を決める
独立性の検定ではカイ二乗分布に従うカイ二乗統計量を使います。ですが、適合度の検定でも見たように理論値が必要です。そこでここでは、理論値を算出する必要があります。
ここでは、仮説より男女の血液型は独立であることから、理論値は男女でそれぞれの血液型が
となっていることです。
ここで、列目の度数の合計を
、
行目の度数の合計を
、全ての度数の合計を
とすると、理論値は以下の式から求められます。
例えば、男性のA型の場合の理論値は
となります。このようにして全ての理論値を求めると、
| 血液型 | A型 | B型 | O型 | AB型 | 計 |
|---|---|---|---|---|---|
| 男性 | |||||
| 女性 | |||||
| 合計 |
となります。
理論値からの実測値のずれを2乗したものを、理論値の値で割り、和をとります。
今回の例では以下のようになります。
4 棄却ルールを決める
のクロス集計表(縦
行、横
列)の場合、自由度は
のカイ二乗分布を用いて検定を行います。
この場合、
となります。独立性の検定は片側検定で行うため、統計数値表からとなります。
5 検定統計量をもとに結論を出す
さて、結論を出しましょう。今回で言えば、有意水準は、P値は
より、有意水準
において、
を棄却し、帰無仮説を採択します。
つまり、「性別と血液型は独立ではないとは言えない(関連があるとは言えない)」と言えます。
下記のグラフは、カイ二乗分布をわかりやすく大雑把に拡大した図なので、本物のカイ二乗分布のグラフとは違うことに注意してください。

まとめ
| 用語 | 意味 |
|---|---|
| 独立性の検定 | 2つ以上の分類基準を持つクロス集計表において、分類基準に関連があるかどうかを検定すること |
| 理論値の求め方 |